
Crow has hosted a variety of workshops designed to encourage community building and interdisciplinary collaborative work among writing scholars.

Our goals are threefold:
- Help teachers integrate data-driven approaches into their classrooms by demonstrating the numerous contexts in which our corpus tools and database can be used for teaching writing;
- Promote writing research by sharing our pedagogical materials with other scholars;
- Share our unique approaches for building sustainable, equitable research teams.
In addition to the materials below, please visit the Crow platform for more how-to documents, screencasts, and other support!
Exploring tense-agreement issues in L2 writing using a learner corpus (Oct 2021)
On October 23rd, 2021, Arizona Crow researchers Anh Dang, Hui Wang, and Ali Yaylali hosted an online workshop at the Arizona Teachers of English to Speakers of Other Languages (AZTESOL) 2021 conference: “Exploring tense-agreement issues in L2 writing using a learner corpus.”
Learn more about this workshop.
Collaborating online: Lessons from a successful team (Mar 2021)
In March 2021, we supported the University of Arizona Women’s Hackathon by creating materials Hackathon teams could use to collaborate more inclusively and effectively.
Based on the experiences of an interdisciplinary software design and research team working at multiple sites, we share three principles for collaborative teams who prioritize inclusivity and mutual respect. Examples and practical techniques will help your team work together more effectively both asynchronously and when working together in person.
See our slides and other resources, created by Crow researchers Michelle McMullin, Shelton Weech, and Bradley Dilger.
Designing Pedagogical Materials Using Interactive Data-driven Learning (iDDL) with Multilingual Learner Corpora (Jul 2020)
We presented a workshop at the TALC 2020 online conference in July 2020.
This 1.5 hour pre-conference workshop is dedicated to teachers and researchers working in foreign/second language instruction. We invite participants who would like to broaden their knowledge and use of a new innovative approach to Data-Driven Learning (DDL), which we call interactive Data-driven Learning (iDDL). More specifically, iDDL is a dynamic way of integrating concordance lines in a scrollbar format into online pedagogical materials using learning management systems (e.g. Moodle, etc) or any other online platforms that support embedding (e.g. Google sites). For those of you who may have attended our TALC 2018 workshop on the Crow corpus, note that this workshop will focus on this new functionality, and that we have updated our corpus and interface extensively in the past two years.
See our workshops category for most recent news.
We hosted a workshop at SSLW 2019 in Tempe, Arizona.
We recently conducted an invitation-only workshop for summer 2019 at Wright State University in Dayton, Ohio.
We also attended Computers & Writing 2019 and Council of Writing Program Administrators 2019.
Exploring variation and intertextuality in L2 undergraduate writing in English: Using the Corpus and Repository of Writing online platform for research and teaching
July 18, 2018
This workshop was conducted at the 2018 TALC (Teaching and Language Corpora) conference in Cambridge, England. For the first time, Crow members debuted a working prototype of our platform. Participants were able to interact with our online interface and provide feedback upon completion of delegated tasks, such as exploring the search and filter functions in our repository database.

Friday Tech Talk: Word And Phrase
February 23, 2018
This workshop, given at the University of Arizona, demonstrated the uses of Word and Phrase, a digital tool which searches for the frequency of words within a text. Our Word and Phrase Handout provides a detailed explanation of how it functions and the various ways it can be used by professors and research scholars.

Integrating AntConc into Teacher Curriculum
February 17, 2018
The Arizona Crow team continued its series of workshops focusing on AntConc, a freeware corpus analysis toolkit developed by Laurence Anthony, with this workshop, given at the 17th Annual SLAT Interdisciplinary Roundtable. Crow researchers demonstrated how to search for N-grams and use concordance functions within AntConc. Our AntConc Handout lists helpful tutorials, useful terminology, and practice activities for using AntConc.
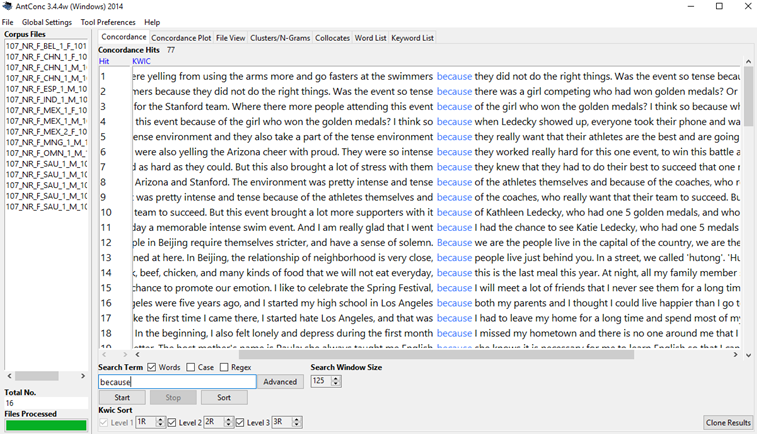
Arizona AntConc Workshop 2017
November 10, 2017
The Arizona team hosted a workshop for instructors which demonstrated how to use AntConc, mentioned above, in several teaching contexts. Instructors were encouraged to consider citations and several other elements of writing in connection with language awareness.
Structuring Active Work: Developing Sustainable Digital Infrastructures for Collaborative Research Teams
June 1, 2017
This workshop, given at the Computers and Writing 2017 conference, shared group communication strategies that research teams can implement to support joint decision-making and sustain long-term research. Participants were able to learn best practices for interdisciplinary collaboration, specifically addressing differences in communication and research methods among different disciplines.
Crow’s Python Programming for Beginners
February 21, 2018
This workshop was given to prepare Crow members for a more advanced training led by a professional programmer. The workshop consisted of three sections. The first section focused on tools installation, i.e. installing Python in Visual Studio; the second section explained the basics of Python programming, such as string and list variables. The last section was based on a hands-on activity, which provided the participants with a chance to write a simplified “tokenizer” on their own. Workshop led by Ge Lan and Tony Bushner.
Rocking the COCA (Corpus of Contemporary American English)
November 12, 2015
This workshop, given at Purdue University to the English Department, focused on how to use Corpus of Contemporary American English for research and pedagogical purposes. We specifically focused on introducing writing instructors to the basic and advanced interface functionalities: searching for collocations, using KWIC, comparing the use of lexical items across registers (speech, academic writing, newspapers, etc.). Slides and handouts from the workshop are available.